随着大数据时代的到来,海量数据的存储、管理和处理成为企业面临的核心挑战。Hadoop分布式文件系统(HDFS)作为Apache Hadoop生态的基石,提供了高可靠、高扩展性的分布式存储解决方案,是大数据处理不可或缺的组件。本文将带您快速入门HDFS,深入解析其数据处理与存储支持服务。
一、HDFS 核心架构与设计理念
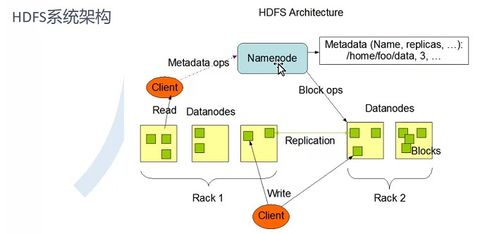
HDFS遵循主从架构,主要由两个核心组件构成:
- NameNode(主节点):作为系统的“大脑”,负责管理文件系统的命名空间(如目录树、文件元数据)并协调客户端的访问。它存储着文件到数据块的映射关系以及数据块在集群中的位置信息。通常配置高可用方案,防止单点故障。
- DataNode(从节点):作为“劳动力”,负责在本地磁盘上实际存储数据块,并执行数据块的读写操作。DataNode定期向NameNode发送心跳信号和块报告,以维持集群的健康状态。
HDFS的设计理念基于几个关键假设:适合存储超大文件(GB、TB级);采用“一次写入,多次读取”的流式数据访问模式;部署在廉价的商用硬件上,通过软件层面的容错机制保障可靠性。
二、HDFS 数据处理与存储的核心机制
1. 数据分块与复制
HDFS将大文件分割成固定大小的数据块(默认为128MB),这些块被分散存储在不同的DataNode上。每个数据块会有多个副本(默认3个),分布在不同的机架或节点上。这种机制不仅实现了数据的并行处理,还通过冗余存储确保了数据的高容错性和可用性。
2. 读写流程
- 写入流程:客户端向NameNode发起写请求,NameNode验证权限后,返回可写入的DataNode列表。客户端将数据块直接写入第一个DataNode,该节点接收后将其转发给列表中的下一个节点,形成流水线复制,直到所有副本写入完成。
- 读取流程:客户端向NameNode请求目标文件的数据块位置信息,然后直接与最近的DataNode建立连接,并行读取数据块,最后在客户端组装成完整文件。
3. 容错与恢复
- DataNode故障:NameNode通过缺失的心跳检测到故障,随后将故障节点上的数据块,利用其他副本重新复制到健康的节点上,确保复制因子不变。
- 数据块损坏:客户端和DataNode通过校验和验证数据完整性。发现损坏时,客户端会从其他副本读取,并报告NameNode,触发损坏块的修复。
三、HDFS 作为存储支持服务的关键特性
- 高吞吐量访问:通过数据分块和并行读写,HDFS优化了大数据集的批量处理性能,特别适合MapReduce、Spark等批处理作业。
- 可扩展性:通过横向添加DataNode,可以轻松扩展存储容量和计算能力,支持从数百到数千节点的集群。
- 成本效益:设计运行于低成本硬件,通过软件实现容错,降低了海量数据存储的总拥有成本。
- 生态系统集成:HDFS是Hadoop生态的核心存储层,与YARN、Hive、HBase、Spark等组件无缝集成,为上层计算框架提供统一、可靠的数据源。
四、快速实践:基础操作命令
通过Hadoop Shell命令,可以快速体验HDFS的基本操作:
hdfs dfs -mkdir /user/test:创建目录hdfs dfs -put localfile.txt /user/test:上传本地文件到HDFShdfs dfs -ls /user/test:列出目录内容hdfs dfs -cat /user/test/localfile.txt:查看文件内容hdfs dfs -get /user/test/localfile.txt .:下载文件到本地
五、与展望
HDFS以其简洁的架构、强大的容错能力和出色的扩展性,奠定了大规模数据存储的基石。对于初学者而言,理解其核心架构、数据存储机制以及与计算框架的协同方式是快速入门的关键。随着云原生和对象存储的兴起,HDFS也在持续演进(如HDFS EC纠删码、与S3的集成),但其作为大数据处理底层可靠存储服务的核心地位,在可预见的未来仍将不可替代。
要深入掌握,建议在搭建的Hadoop集群上亲手实践,并结合具体项目理解其在完整数据流水线中的应用。