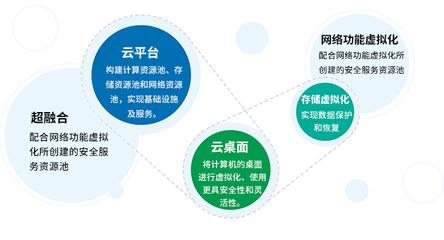
百分点作为大数据与人工智能领域的领先企业,其亿级个性化推荐系统的发展历程反映了从早期简单规则引擎到当前智能、实时、可扩展系统的演变。系统的发展可以划分为三个阶段:初始阶段(2010-2013年),基于用户基本行为和规则进行推荐,注重数据处理的基础构建;成长阶段(2014-2017年),引入机器学习和协同过滤算法,逐步集成实时数据流处理;成熟阶段(2018年至今),采用深度学习和多模态数据融合,支持亿级用户的高并发、低延迟推荐。这一历程得益于数据处理技术的飞速发展,包括大数据框架如Hadoop和Spark的应用,以及云原生架构的采用。
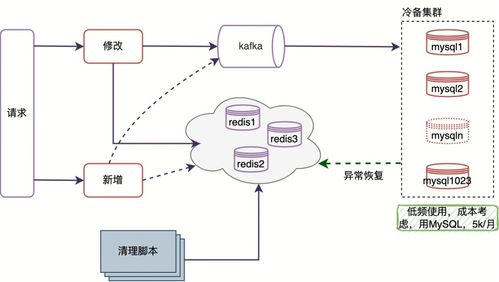
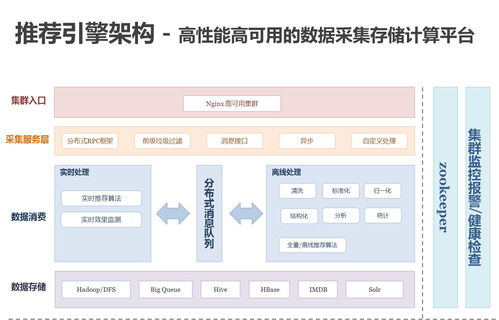
在实践架构方面,百分点的推荐系统采用模块化、分层设计,确保高可用性和弹性扩展。整体架构主要包括数据采集层、数据处理层、算法层、服务层和应用层。数据采集层负责从多渠道(如Web、移动端)收集用户行为数据,使用日志收集工具如Flume和Kafka实现实时数据传输。数据处理层是关键支撑,涵盖批处理和流处理两部分:批处理使用Hadoop和Spark进行历史数据清洗和特征工程,生成用户画像和物品特征;流处理借助Flink或Spark Streaming处理实时事件,如点击和浏览行为,以快速更新推荐模型。存储支持服务采用混合方案,包括HDFS用于大数据存储,Redis和Cassandra用于缓存和实时数据查询,以及Elasticsearch支持快速检索,确保数据的高效访问和持久化。
算法层是系统的核心,集成多种推荐算法,如协同过滤、基于内容的推荐和深度学习模型(例如神经网络和强化学习),通过A/B测试框架优化模型性能。服务层通过微服务架构暴露API,使用Docker和Kubernetes进行容器化部署,实现负载均衡和自动扩缩容,保障系统在高并发场景下的稳定性。应用层则为最终用户提供个性化推荐界面,集成到电商、媒体等业务平台中。
百分点的亿级个性化推荐系统通过演进式的技术迭代和稳健的架构设计,实现了高效的数据处理与存储支持,这不仅提升了用户体验,也为企业提供了可扩展的解决方案。未来,随着AI技术的进步,系统将进一步融合多源数据并强化实时智能,以应对更复杂的业务需求。