随着企业数字化转型的深入,数据中台作为企业数据能力的核心载体,其结构化大数据的存储设计与处理支撑服务成为关键。本文将从结构化大数据的特点出发,探讨存储架构的设计原则、技术选型及数据处理服务的支撑机制。
一、结构化大数据的特点与存储挑战
结构化大数据通常指具有明确定义模式的海量数据,如交易记录、用户信息、日志数据等。其特点包括数据量庞大、读写频繁、schema相对固定但可能演进。存储设计需应对高并发、低延迟、水平扩展及数据一致性等挑战。
二、存储架构设计原则
- 分层存储:根据数据热度和访问频率,采用多级存储策略,如热数据存于内存或SSD,冷数据存于HDD或对象存储。
- 分布式架构:利用分布式数据库或数据仓库(如ClickHouse、Apache Doris)实现水平扩展,支持PB级数据存储。
- Schema管理:支持灵活的schema演进,通过Avro、Protobuf等格式保障数据兼容性。
- 数据分区与索引:按时间、业务键分区,结合二级索引提升查询效率。
三、技术选型与实践
- 在线事务处理(OLTP):可选NewSQL数据库(如TiDB、CockroachDB)或传统关系型数据库分库分表。
- 在线分析处理(OLAP):采用列式存储数据库(如ClickHouse、Apache Druid)或数据湖架构(如Iceberg、Hudi)。
- 存储引擎优化:结合压缩算法(如ZSTD)、编码技术减少存储空间,提升I/O性能。
四、数据处理与存储支撑服务
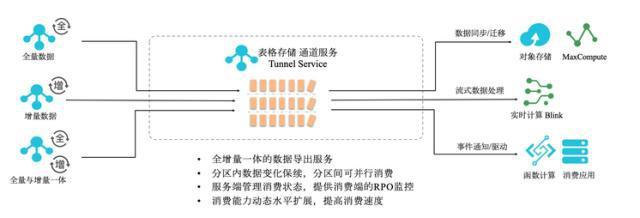
- 数据集成服务:通过CDC(Change Data Capture)、ETL工具实现多源数据实时同步与批量导入。
- 计算引擎支撑:集成Spark、Flink等计算框架,支持流批一体处理,满足实时分析与离线挖掘需求。
- 数据治理与元管理:建立数据目录、血缘追踪、质量监控体系,保障数据可信可用。
- 服务化接口:提供RESTful API、SQL查询接口,降低业务方使用门槛,促进数据赋能。
五、总结与展望
结构化大数据存储设计需平衡性能、成本与易用性,而数据处理支撑服务则需实现数据从采集到消费的全链路管理。随着云原生、AI增强管理技术的发展,数据中台存储与处理服务将更加智能化、自动化,成为企业数据驱动决策的坚实基石。